· knowledge · 11 min read
The Modern Data Stack - an introduction
Learn about the Modern Data Stack, and how it can help your business transformation from an centralized, IT centric data infrastructure to a decentralized, business focused data infrastructure.

The Modern Data Stack - what is all the hype?
The modern data stack enables agility, at least that is what everyone says. But what exactly is the Modern Data Stack?
The truth is, that it is not one singular thing. Instead, it is a paradigm, which puts the end user and data consumer in focus. So, how does the modern data stack achieve this? By leveraging plug-and-play SaaS & Cloud offerings, thereby lowering the implementation burden of data projects. It achieves this by having the following mindset:
- Focus on business goals, not IT solutions with pre-built integrations
- Leverage cloud elasticity - no more code-first ETL pipelines needed, just SQL and t-shirt sizes
- Catalogue and govern, making data findable and understandable
The setup - modular components
In order to understand the modern data stack, consider the diagram
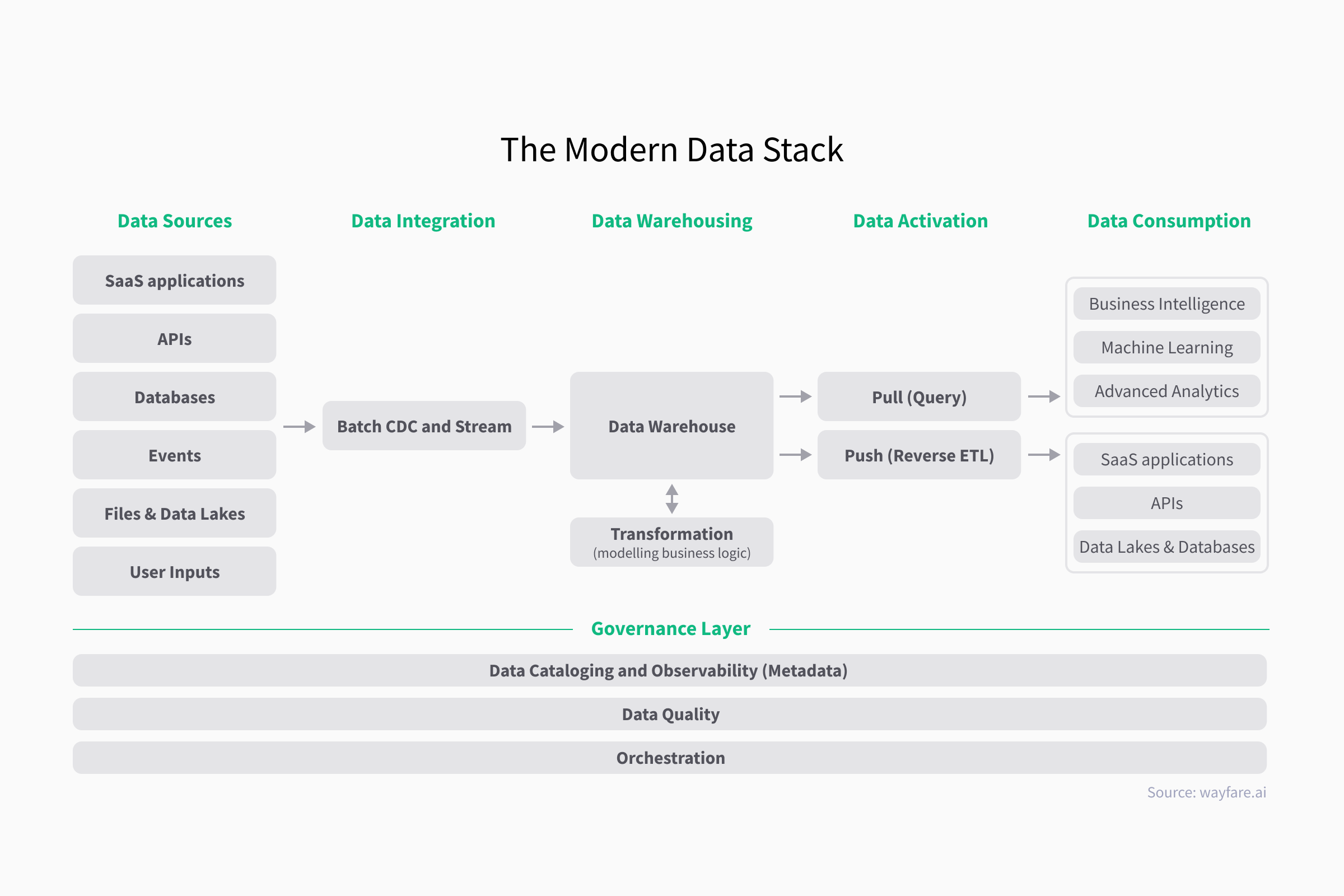
As seen above, we can somewhat categorize the different abstract steps in the modern data stack as:
- Sources
- Integration
- Warehousing
- Transformation (Inside the DWH)
- Activation
- Consumption
With supporting governance & usability functions such as:
- Data Catalogue
- Data Quality
- Orchestration
Obviously, this can be implemented in various ways. A core outcome of the modern data stack is agility. To achieve this, it can be beneficial to adopt SaaS and out-of-the-box providers to implement the various layers.
An example of one such set of providers (technologies) to implement could be:
- Fivetran (Integration)
- DBT (Transformation, Data Quality)
- Snowflake (Data Warehousing)
- Hightouch (Activation)
- Prefect (Orchestration)
- Atlan (Metadata & Catalogue)
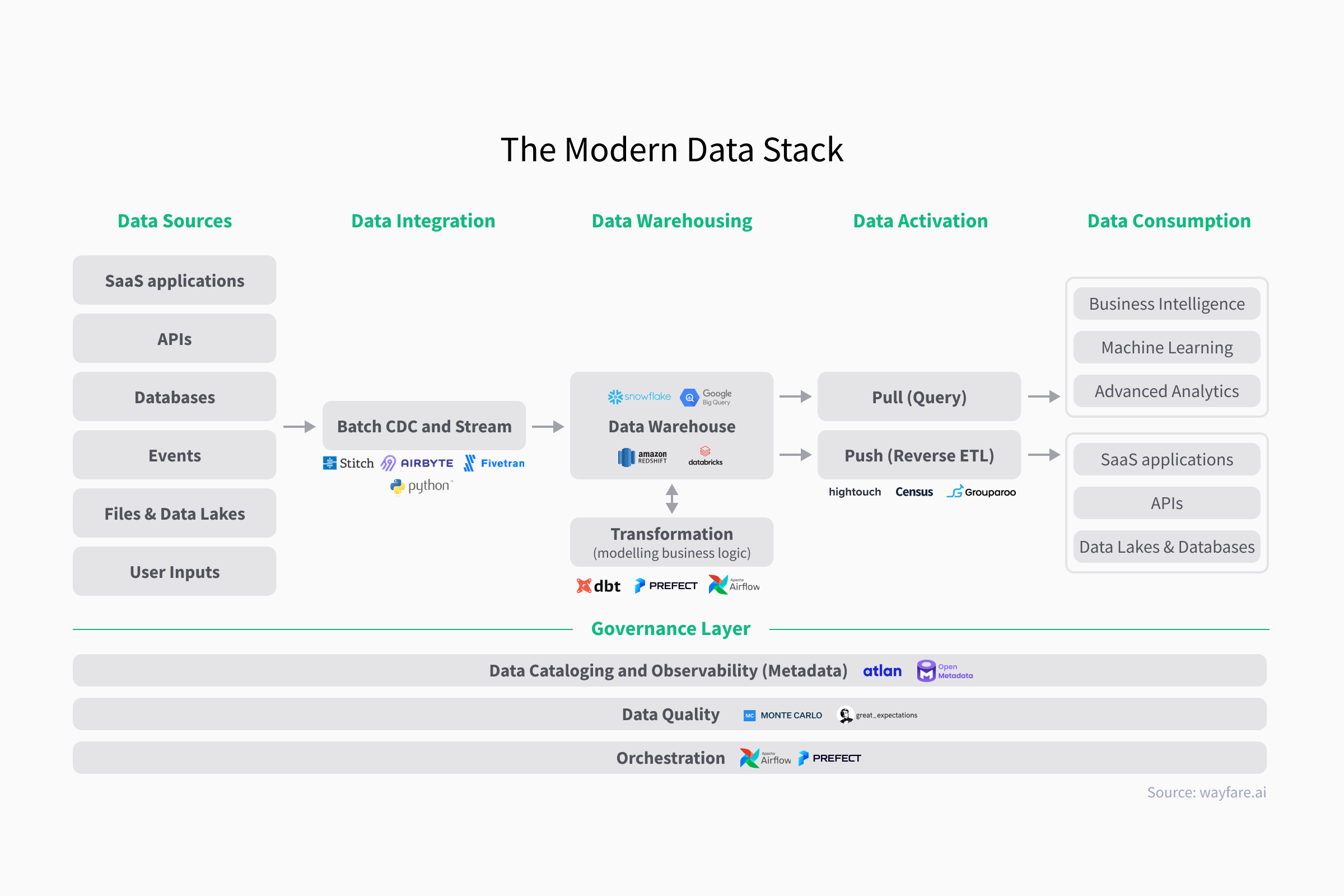
One thing to look out for is to choose a core stack that integrates well. For instance Prefect, a leading code-first workflow engine and platform, has great support for e.g., dbt.
Another thing is to find a stack that makes it easy to include as much of the business as possible. By this, we mean that analysts, data consumers, and AI engineers should be part of the implementation cycles as much as possible to reap the full benefits.
Of course, this is not a hard requirement. Analysts may not want to dive into DevOps and deployments of workflows, but they most definitely care about data quality and end-results.
Data Integration layer
One of the absolutely most important steps in becomming data-driven is aggregating, storing, and making data readily accessible, paired with built-in governance.
If you have many different data sources - different RDBMS, SaaS applications, file shares, or data lakes (maybe even multi-cloud) to name a few - this can be quite a challenge if you choose to implement this from scratch with code.
Choosing integration services such as wayfare.ai, Fivetran, Quix or Airbyte can help you achieve your goals. These are SaaS offerings which offer integration-as-a-service.
With these, users can easily:
- Add new data to the data warehouse
- Keep data up to date
- Ensure good practice for change data capture (CDC)
This allows you to focus on business outcomes and desired data rather than code, testing, and best-pratice oversight.
DWH and Transformation layer
History
In the 1990s all the way to the mid 2010s, the use of ELT (processing data in DB/DWH) was largely only possible for expensive, hard to operate, enterprise-grade DWH and cube technologies, and required technical excellence to optimize.
Scaling a large database required large up-front investment (pay 24/7), so when hadoop and spark became widely available many companies jumped on the opportunity to process data at scale - though this came at a cost of significant amounts of developer time, as these are code-first approaches to data pipelining.
Data Warehousing
In the early 2010s the cloud data warehouse movement took off, lead by Google BigQuery and Snowflake. The separation of storage and compute in the cloud data warehouses allowed for processing massive amounts of data, without paying for a massive database to match.
When a user needs to process a large dataset, they now start a large compute instance (t-shirt sizes in snowflake terminology), process their job, write their dataset, and then shut down the instance. They only pay for what they use, i.e. pay-as-you-go. This lowered the total cost significantly - see the chart below.
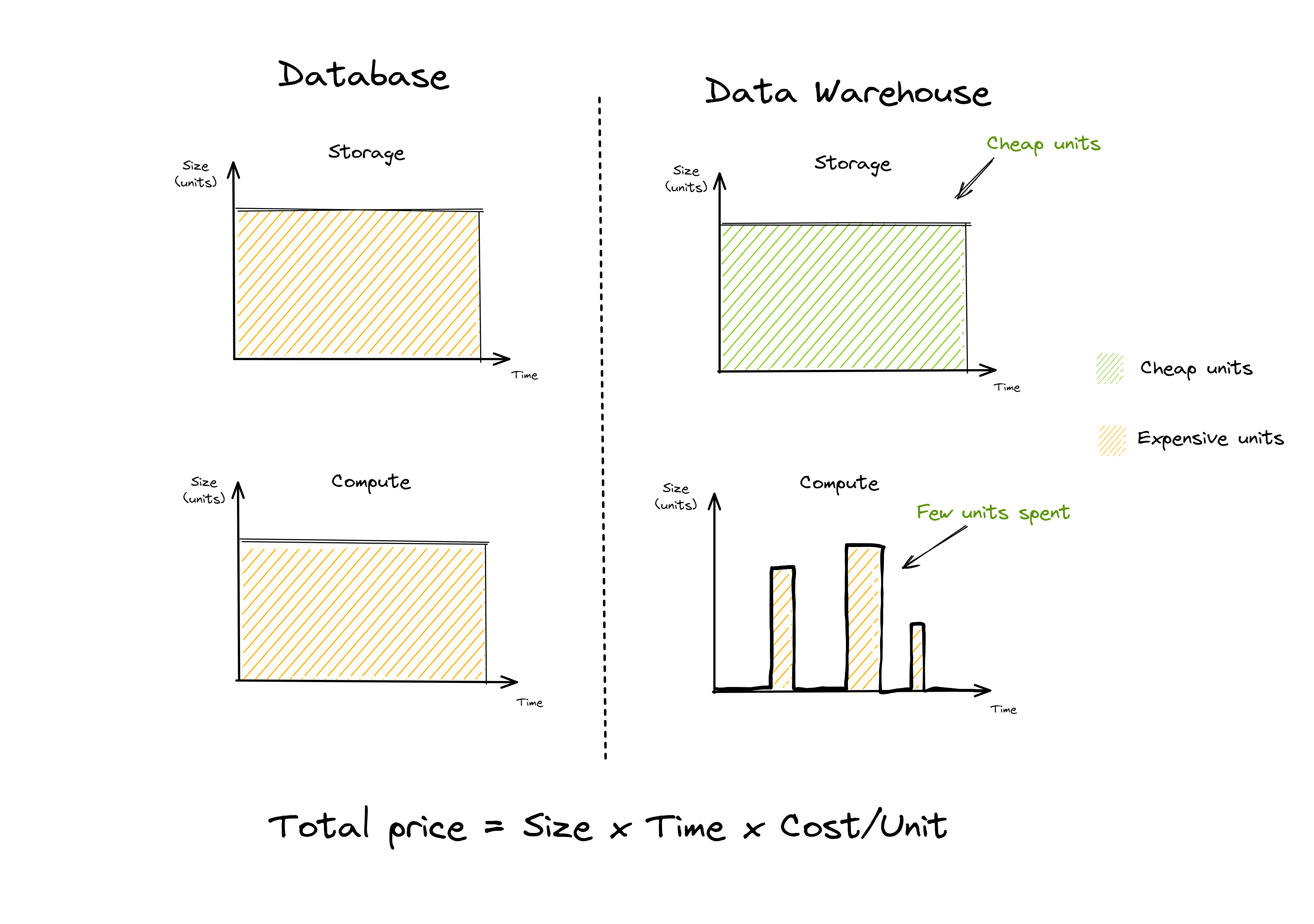
Since the innovation in cloud data warehousing allowed for a serverless approach to processing data with SQL, the need for data engineering and developers has decreased for many use cases, such as BI and Analytics.
Of course, use cases still exist where a DWH is the wrong choice, but for a lot of them, this was and is a great improvement - because now data pipelines could be defined as SQL statements declaratively.
Enter dbt - Data Build Tool
In the late 2010s, dbt innovated the transformation layer in the DWH by introducing semantic models and a way of developing data pipelines with an experience that is familiar to software developers.
Introducing tooling for templating macros, or running multiple dependent queries in parallel and in the right order, implementing unit tests, and much more.
This has quite quickly become an industry standard, and most modern analytics engineering approaches, such as the modern data stack, usually rely on dbt as the transformation layer.
dbt, which is made by dbt labs, is open source at its core, but also has a paid cloud offering.
A really popular feature that came with dbt was data lineage graphs and data documentation. Using dbt, you get a trustworthy set of documentation for your macros, tests, and lineage on a table level.
A key benefit of DBT is that it is based on SQL, allowing analysts to be be part of the process. Moreover, unlike offerings such as Azure Data Factory, it promotes great DevOps and quality as well.
The way forward for DWH and Transformation
We believe that the models introduced and popularized by dbt will continue to work - it implements quality into the data life cycle, and enables documentation. But some things remain to be desired, such as per-field lineage and more advanced catalogue features.
With an increased focus on data privacy and the various rights to access, rectification, and erasure (GDPR), or KYC-like use cases, it becomes even more critical every year to understand where data is coming from. In banking and trading, it is a requirement that every field source is documented all the way from the mainframe source in some cases.
There is still room for improvement in regulatory contexts (e.g., GxP in pharma) where audit logs and traceablity sometimes can be a pre-requisite for license to operate.
At wayfare.ai, we take this as a challenge and seek to build out the worlds first automated field-level lineage graph in the transformation layer.
Reverse ETL - the last mile
In order to actually use the data, Reverse ETL is the process of “activating” data in the data warehouse upon update. This could mean updating CRM accounts with new targets when they are updated in the warehouse or some other system that can use the data.
It is effectively the step that operationalizes data, helping to drive business value.
Reverse ETL comes with a lot of potential pitfalls when implementing it yourself from scratch, such as the many different potential targets, how to make sure you only update changed data, how to delete records (e.g., in a GDPR context). To mitigate these pitfalls, consider choosing a vendor or dedicated tool for this, rather than building it from scratch.
Proprietary industry leaders in Reverse ETL are Hightouch and Census, and they offer a lot of functionality to get up and running.
At wayfare.ai, we also implement Reverse ETL as a service, allowing you to connect your data to your systems after processing, greatly increasing the business value of your data.
Why not move data directly from source to BI?
Integrating into your Data Warehouse, transforming it there, and then consuming with Reverse ETL comes with a lot of advantages. With this structure, you effectively help break down silos of data, and reduce duplication from manual integration or copy activities, helping you achieve time-to-action targets while reducing manual labour and mitigating the risk of actions based on incorrect/outdated data.
The governance layer - ensuring usability
A core value of the modern data stack is self-serviceability and agility. This is only possible through great governance. But governance can come in many forms, be it processes, supporting tooling, or policies.
We break governance functionality into three main categories:
- Data Catalogue
- Data Quality
- Orchestration
Each of these are essential to the modern data stack, and the value of them should not be underestimated.
Let’s review what we mean:
Data Catalogue - making data findable and understandable
With data catalogue, you essentially enrich objects in your stack with metadata:
- Datasets in your data warehouse
- Relations (lineage)
- Data flows
- Schedules
and document them. This process should be as automatic as possible, to ensure adoption (to Product Owners: No-one in your teams likes maintaining a wiki manually, No-one).
dbt provides some of this, and other toolings such as atlan or open metadata also provide good foundations to build this.
At wayfare.ai, we automatically organize and catalogue data lineage, documentation, sources, flows and so forth in an easy to search & navigate, embedded system. Easily find related data or search for field names throughout your organisation.
Data Quality
It might seem quite obvious that a pre-requisite for turning data into business value is to ensure the quality of the data itself. It might not be obvious, however, that the approach to data quality is changing.
In the modern data stack, tools like dbt and Great Expectations have introduced the notion of “expectations” of columnar data.
For instance, during your data flow, you might create an inner join between two data sources. If the sync messed up, and one of the staging tables are empty, the result will be an empty table.
To avoid downstream issues from this, you should implement data quality through tests. These can be done at application layer, or throughout your data flow as unit tests.
Another example might be that your customer table has an “age_years” property. It would be quite bad if this property was greater than 200 or negative, and could potentially impact downstream automated processes if quality messes up. By implementing a test, or “expectation” for this table that “age_years” should be between, lets say, 18 and 115, and not empty/null, you effectively mitigate the issue of bad BI aggregates in automated workflows from happening.
Currently, most solutions for data quality gives a monitor, measure and react layer - but generally they tend to lean towards code-first approaches.
At wayfare.ai, we believe that unit tests should be easy to embed at any stage of your data flow, and should be implementable by non-developers and developers alike. This is why we built-in data test functionality as a core pillar of our product.
Orchestration
From CRON and proprietary orchestration platforms, we have come a long way in 2022. From the inception of code-first platforms like Airflow (by Airbnb) or Luigi (by Spotify), which innovated and effectively changed orchestration setups for the better, to next-gen orchestration platforms like Prefect and Dagster, who are paving the way for an even better developer experience and enabling even more complex workloads at a very fast rate.
Many tools in the integration world generally include an orchestration layer of some sort. It might be very capable, or more limited.
Tools such as Azure Data Factory provide orchestration and DAG-like setups, but the amount of pre-built tasks is rather limited compared to an orchestration engine like Prefect.
At wayfare.ai, we understand that data should not just end in systems, but activities such as updating data should be able to trigger events for e.g., running Azure ML pipelines - or if a data quality check fails, we should hit a custom webhook to slack or operation tools. This is a core feature of our platform.
Conclusion
There are many good tools to assist in implementing the modern data stack as a process for driving business value, maybe even too many. Some of these are very complex, but generally they all integrate with other tools to lift a broader workload.
There is space for a complete end-to-end modern data stack tool, that can integrate with other tools when it falls short. This is why we built wayfare.ai.
With wayfare.ai, you can accelerate the journey towards a more agile and inclusive way of working with data, but without tool fatigue and large implementation costs.
Explore wayfare.ai, the single tool needed to get your Modern Data Stack
With wayfare.ai, you get plug-n-play integrations for all your data sources and data warehouses. We automatically build a data catalogue, and keep your data up-to-date.
No more tool fatigue - let your teams collaborate across functions in a single, familiar setting with wayfare.ai.

